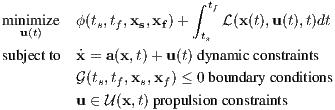
ABSTRACT
Recently within the aerospace industry, several demonstrations of successful soft, upright rocket landings have taken place; namely by SpaceX and Blue Origin. In this paper, such an application is examined through the scope of trajectory optimization and nonlinear programming. A general dynamical model of a rocket, equipped with a single thruster capable of gimbaling, is formulated. A direct method of discretizing state-time dynamics is applied to the dynamical model, from which a nonlinear program is developed. Using gradient based optimization, the nonlinear program representing the landing of a rocket is optimized with the objective of minimizing the rocket’s propellant expenditure, while abiding to the constraints of landing softly at the location of its target. It is shown that this paper’s dynamical model and trajectory optimization method yield optimal propellant expenditures comparable with that of literature.
Index Terms— Trajectory Optimization, Direct Methods
1.
The applications of trajectory optimization range from lunar landings to robotic locomotion. Through the developments of space exploration over the past few decades, new methods of spacecraft trajectory optimization of come to surface. Trajectory optimization problems have been tackled from a variety of perspectives, for example: optimal control [?], machine learning [?], and convex programming [?]. This paper takes the perspective of gradient based optimization.
2.
Conventionally, in the case of a planetary lander, or in this case a rocket returning to Earth, trajectory optimization is performed using either direct or indirect methods. 2.1.
Indirect methods operate by first analytically constructing the necessary and sufficient conditions for optimality pertaining to the particular problem at hand, then secondly discretizing these conditions to formulate a constrained parameter optimization problem. Most often in the case of a planetary lander or the like, these necessary conditions are derived from Pontryagin’s minimum principle [?]. This principle states that, at every moment in time the dynamical system’s control should be chosen to maximize the Hamiltonian of the system. The reader is advised to consult [?] for my information about this method. 2.2.
Direct methods operate by discretizing the trajectory optimization problem directly, in order to formulate a constrained parameter optimization problem. Direct transcription methods, in general, have several advantages over indirect transcription methods. The necessity to analytically determine initial costate variables is circumvented, and the optimization problem size is reduced by a factor of two. One of the most significant merits is that, one does not need to specify the structure of the problem, a priori. In general, direct transcription methods are very robust and are able to converge to optimal solutions from poor initial guesses.
2.3.
For a general dynamical system, the problem of trajectory optimization is formulated as
|
|
Essentially, this formal formulation asks for the control at every
moment in time u(t) in order to minimize the initial and terminal
costs ϕ(ts,tf,xs,xf) and the path costs ∫
tstf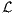 (x(t),u(t),t)dt,
all while abiding to dynamic constraints and boundary constraints,
which are all dictated by the state of the dynamical system x(t).
For the case of a rocket landing, it is quite obvious that the
boundary constraints would mandate that the rocket’s final state
x(tf) be equal to the rocket’s target state, which is chosen
beforehand. The rocket’s dynamic constraints are not as
intuitive, and are derived from the way in which the system is
discretized.
(x(t),u(t),t)dt,
all while abiding to dynamic constraints and boundary constraints,
which are all dictated by the state of the dynamical system x(t).
For the case of a rocket landing, it is quite obvious that the
boundary constraints would mandate that the rocket’s final state
x(tf) be equal to the rocket’s target state, which is chosen
beforehand. The rocket’s dynamic constraints are not as
intuitive, and are derived from the way in which the system is
discretized.
2.4.
Following the common notation of optimal control, the trajectory of dynamical system can be formulated as a system of time-varying variables.
![[x(t)]
z = u(t)](TemplateICATT1x.png)
2.4.1.
The way in which the dynamical system evolves over time is described by the system dynamics. These dynamics, for the scope of this paper’s discussion, are described by a system of ordinary differential equations, more commonly known as state equations. The state equations, in their generic form, are written as
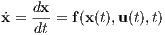
2.4.2.
In the problem of trajectory optimization, two conditions must be strictly satisfied. That is, that the system’s initial dynamic variables
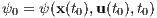
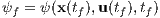
2.4.3.
In many dynamical systems, the problem of trajectory optimization leads itself to path constraints. These path constraints can range from obstacle avoidance in quad-copters to trajectory energy in spacecraft Lagrange point insertions. These path constraints can be formally stated as
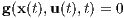
2.4.4.
Of course, for many reasons it is necessary to bound a trajectory optimization problem, including, but not limited to: hardware constraints and simulation constraints. For example, one would bound the angular velocity of their fictional spacecraft so that it is not spinning into eternity. Additionally, one may want to place rectangular bounds on the environment of their spacecraft’s simulation, for example: a spacecraft’s position should be within the solar system. Aside from state constraints, there are also control constraints. In the case of the reusable rocket being examined in this paper, these constraints would be magnitude and direction of the rocket’s thrust. The bounding on the system’s state is formulated as
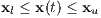
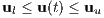
2.4.5.
The whole point of trajectory optimization is select a control policy u(t) to minimize or maximize some measure of performance. In some cases, this measure of performance might be the time to travel from a starting location to an ending location in a dynamical system such as a quad copter. In the case of the rocket landing problem being investigated in this paper, the measure of performance is, of course, propellant expenditure. That is, the goal of the trajectory optimization process is to softly land the rocket at its target, while utilizing as little fuel as possible. For a general dynamical system, the path cost or objective function is defined as
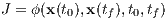
2.5.
In direct transcription methods, the continuous state x(t) and control u(t) are discretized into a finite dimensional description. Through this technique, the original optimal control problem is transformed into a nonlinear programming problem (NLP). For the sake of intuition, transforming the nonlinear programming problem back to an optimal control problem would be akin to having an infinite quantity of states, controls, and constraints.
2.5.1.
The first step in transforming a continuous optimal control problem into a finite dimension nonlinear programming problem is to define the resolution of the discretization n, or the number of nodes. Including the statement of the dynamical system’s simulation starting time tI and final time tF. From these statements, one can formulate the time grid
![[t1,t2.,...,tn]](TemplateICATT9x.png)
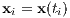
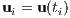
2.5.2.
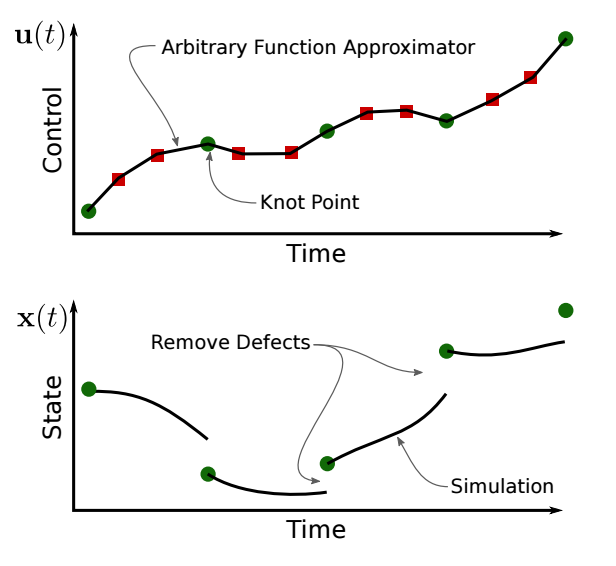
Once the system’s original optimal control description has been transcribed through direct transcription, the values of the system’s states xi and controls ui are represented by a (possibly) large set of NLP variables. The aforementioned bounds on both the system’s state and control are simply instantiated at each node n in the discretization. Perhaps the most crucial part of this direct trajectory optimization process is enforcing the system’s inherent dynamics at each node. That is, an analytical quadrature procedure is used to compare the system’s states at collocated nodes, in order to asses the validity of the optimizer’s placement of each of the system’s states. The schematic of this process can be seen in Figure 1.
As previously noted, under the direct transcription process, in which the system’s continuous state and control descriptions are transformed to a finite dimensional parameter constrained problem, a single NLP decision vector is dealt with. This decision vector is formulated as
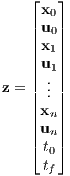
2.6.
In order to compute the defects at each node in the grid space, a method to analytically propagate the system’s dynamics is used. In this paper, herein the method of trapezoidal quadrature will be used. Within the grid space, at node n, the defect is defined as
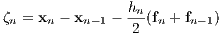
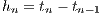
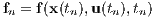
3.
In order to optimize the trajectory of a rocket, it is first necessary to construct a dynamical model, which accurately describes a rocket’s dynamics. 3.1.
It is appropriate to begin with defining the possible controls which the optimizer can take. In the case of a rocket, the main control is its thruster. While many thruster configurations exist for rockets, a common one to assume is a single thruster situated about the rocket’s tail end, capable of gimbaling. With this configuration, in the reference frame of a rocket’s body, the resulting control vector is formulated as
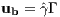
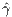 is the direction of the thrust in the body’s frame and Γ is
the magnitude of the thrust. The controls at any moment in time
are defined as the thrust magnitude Γ, inclination angle η, and
azimuth angle ζ, describing the thrust vector in the body frame
as
is the direction of the thrust in the body’s frame and Γ is
the magnitude of the thrust. The controls at any moment in time
are defined as the thrust magnitude Γ, inclination angle η, and
azimuth angle ζ, describing the thrust vector in the body frame
as
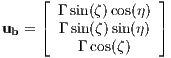
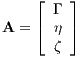
3.2.
It is sufficient to model the rocket as a cylinder, where the length of the rocket is l and the radius of the rocket is r. 3.2.1.
Firstly, it is necessary to establish some coordinate conventions. Firstly, the primary inertial reference frame is defined as a stationary reference frame, from which a body (i.e. the rocket) will be measured in reference to. The Z axis is defined as being directed upward, out of the ground, towards the sky. The X and Y axes are arbitrarily directed, completing the triad forming the right handed coordinate system.
The rocket’s z axis is taken to be directed from the rocket’s tail to its nose, centered about its center of mass (i.e. halfway along the rocket’s length for this discussion). Again, as with the inertial coordinate system, the rocket’s x and y axes are arbitrarily defined to complete the triad, forming the right handed coordinate system. With these conventions, rotations about the rocket’s z axis is known as rolling, and rotations about the x and y axes describe pitching and yawing (somewhat arbitrarily since the rocket is axisymmetric).
The rocket’s orientation in space with respect to the inertial frame of the simulation is robustly described using quaternions, rather than Euler angles, which often become vexatious due to their inherent propensity to encounter singularities. Taking the body’s z axis to be along its axial direction, positively away from the thruster’s location, and the x and y axes to be arbitrarily directed orthogonally to the z axis, completing the right-handed triad, the quaternion can be formulated as
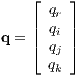
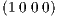 T describes the body’s orientation to be in
alignment with the inertial frame. Note that, as part of the NLP
constraints, qr2 = qi2 + qj2 + qk2. The resulting rotation matrix,
describing the unit vectors of the body’s axes, is computed as
T describes the body’s orientation to be in
alignment with the inertial frame. Note that, as part of the NLP
constraints, qr2 = qi2 + qj2 + qk2. The resulting rotation matrix,
describing the unit vectors of the body’s axes, is computed as
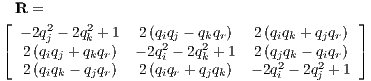 |
Modelling the rocket as a cylinder with length l and radius r, the three-dimensional inertia tensor can be formulated as
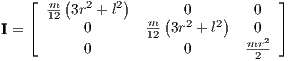
3.3.1.
Having constructed the robust quaternion based rotation matrix, the translational force due to the rocket’s control vector in its local frame ub can be described in the global inertial frame by premultiplying it by the aforementioned rotation matrix as follows
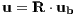
 T, the moment imparted by the control
is
T, the moment imparted by the control
is
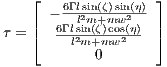
3.3.2.
Having developed the model of the physical influences particular to the rocket environment, the full equation of translational motion is shown as
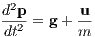
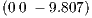 T is the
acceleration due to gravity, and m is the mass of the rocket
governed by
T is the
acceleration due to gravity, and m is the mass of the rocket
governed by
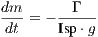
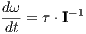
![dq 1[ 0 ]
-dt = 2 ω ⊗q](TemplateICATT31x.png)
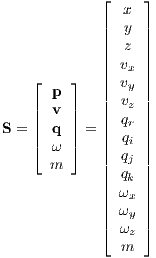
The state of the dynamical system, particular to the rocket, can be formalized as follows
4.
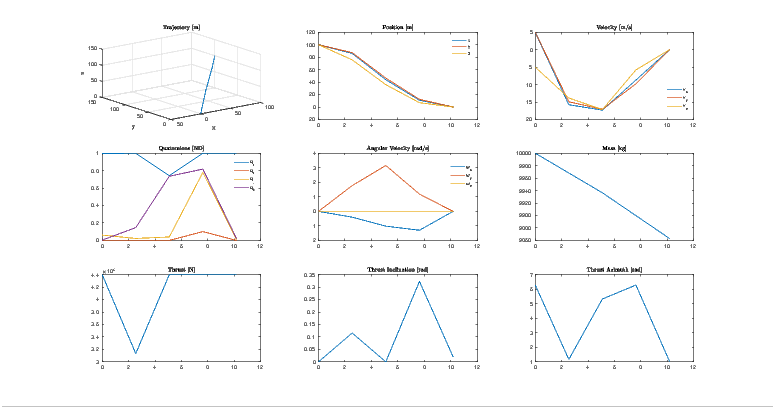
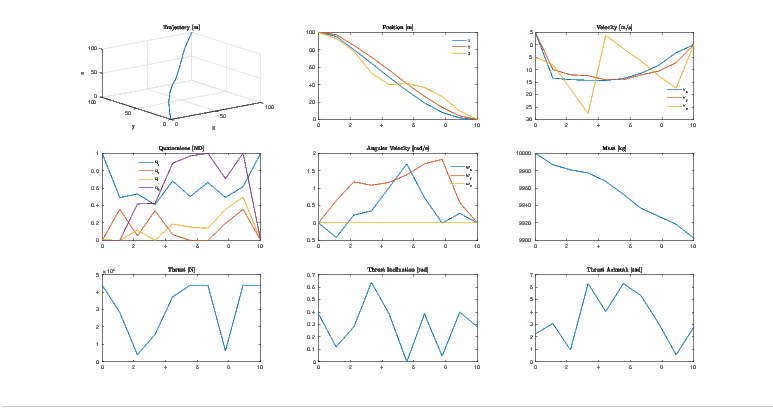
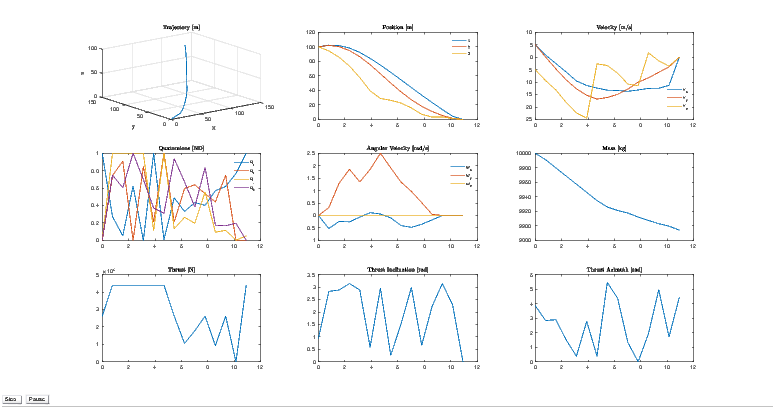
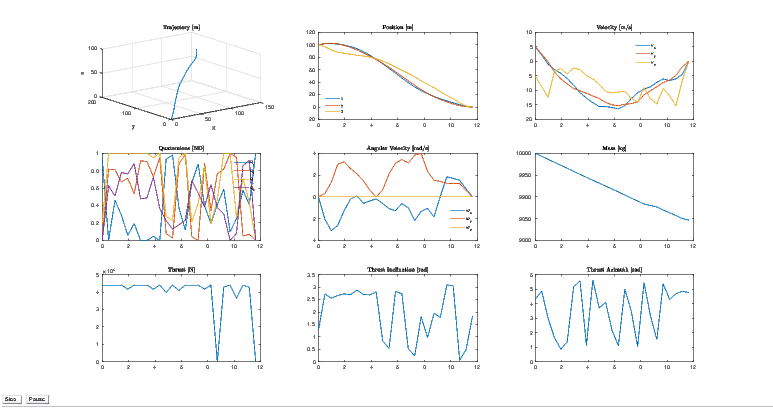
Herein, in the analysis of this paper, the rocket’s state is initialized as
![x = [100,100,100,5,5,- 5,1,0,0,0,0,0,0,10000]T](TemplateICATT33x.png)
![T
x = [0,0,0,0,0,0,1,0,0,0,0,0,0,None]](TemplateICATT34x.png)
![LB = [- 1000,- 1000,0,- 100,- 100,- 100,
x T
0,0,0,0,- 100,- 100,- 100,0]](TemplateICATT35x.png) |
![UB = [1000,1000,1000,100,100,100,
x T
1,1,1,1,100,100,100,10000]](TemplateICATT36x.png) |
![LB = [0,0,0]T
u](TemplateICATT37x.png)
![UBu = [44000,π,2π ]T](TemplateICATT38x.png)
5.
This paper demonstrated a feasible trajectory optimization methodology to replicate the soft, upright landing of a rocket, as first demonstrated by SpaceX and Blue Origin. Future improvements will include the migration to a low-level language, such as C++, to save on computational expenses. Additionally, different methods of transcription will be added to the current software library. And lastly, the software library will abstract itself to more general usage for such applications as interplanetary spacecraft trajectory optimization and quad-copters.